
Inbred, gibberish or just MAD? Warnings rise about AI models / Photo: Fabrice COFFRINI - AFP/File
 Kenya's economy faces climate change risks: World Bank
Kenya's economy faces climate change risks: World Bank

 'Alter-Ego': An Italian hospital's little robot carer
'Alter-Ego': An Italian hospital's little robot carer

 No vaccine, conflict, mistrust: Ebola's return to DR Congo
No vaccine, conflict, mistrust: Ebola's return to DR Congo

 New Zealand minister defends fishers after two orcas killed in net
New Zealand minister defends fishers after two orcas killed in net

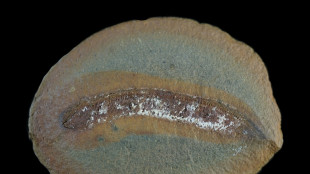 Fossils challenge assumptions on how animals adapted to land
Fossils challenge assumptions on how animals adapted to land
 Al-Qaeda-linked jihadists attack Niger airport, 11 soldiers killed
Al-Qaeda-linked jihadists attack Niger airport, 11 soldiers killed

 Ghana pushes for concrete slavery reparations
Ghana pushes for concrete slavery reparations

 AI-generated videos wield Down syndrome to make sales
AI-generated videos wield Down syndrome to make sales

 Man dies, trains and classes disrupted as heatwave hits France
Man dies, trains and classes disrupted as heatwave hits France

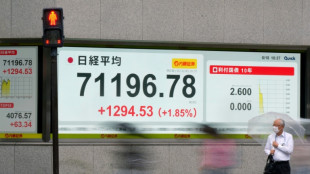
 Swiss central bank holds interest rates, with eye on currency risks
Swiss central bank holds interest rates, with eye on currency risks

 Bank of England follows Fed in holding interest rate
Bank of England follows Fed in holding interest rate

 Range raises $8.3M Series A to unify treasury, risk and compliance across stablecoins and fiat
Range raises $8.3M Series A to unify treasury, risk and compliance across stablecoins and fiat

 Bird flu kills 13,000 seal pups on remote Australian island
Bird flu kills 13,000 seal pups on remote Australian island

 Drastic restrictions on public transport take effect in Cuba
Drastic restrictions on public transport take effect in Cuba

 Robots pour cocktails and run marathons, but still can't multitask
Robots pour cocktails and run marathons, but still can't multitask

 Castro gives crucial backing to Cuba reforms
Castro gives crucial backing to Cuba reforms

 Qantas to launch non-stop Sydney-London flights in October 2027
Qantas to launch non-stop Sydney-London flights in October 2027

 US Federal Reserve holds rates steady, raises inflation expectations
US Federal Reserve holds rates steady, raises inflation expectations

 Military salutes and K-pop madness shake up Colombia campaigning
Military salutes and K-pop madness shake up Colombia campaigning

 England's World Cup opener puts Spanish resort on beer alert
England's World Cup opener puts Spanish resort on beer alert

 Plague was killing hunter-gatherers 5,500 years ago: study
Plague was killing hunter-gatherers 5,500 years ago: study

 What happens when the Strait of Hormuz re-opens?
What happens when the Strait of Hormuz re-opens?

 Spain logs third-warmest year on record in 2025
Spain logs third-warmest year on record in 2025

 Groundbreaking US astronaut Christina Koch wins top Spanish award
Groundbreaking US astronaut Christina Koch wins top Spanish award

 Sovereignty fears dog AI enthusiasm at France's Vivatech
Sovereignty fears dog AI enthusiasm at France's Vivatech

When academic Jathan Sadowski reached for an analogy last year to describe how AI programs decay, he landed on the term "Habsburg AI".
The Habsburgs were one of Europe's most powerful royal houses, but entire sections of their family line collapsed after centuries of inbreeding.
Recent studies have shown how AI programs underpinning products like ChatGPT go through a similar collapse when they are repeatedly fed their own data.
"I think the term Habsburg AI has aged very well," Sadowski told AFP, saying his coinage had "only become more relevant for how we think about AI systems".
The ultimate concern is that AI-generated content could take over the web, which could in turn render chatbots and image generators useless and throw a trillion-dollar industry into a tailspin.
But other experts argue that the problem is overstated, or can be fixed.
And many companies are enthusiastic about using what they call synthetic data to train AI programs. This artificially generated data is used to augment or replace real-world data. It is cheaper than human-created content but more predictable.
"The open question for researchers and companies building AI systems is: how much synthetic data is too much," said Sadowski, lecturer in emerging technologies at Australia's Monash University.
- 'Mad cow disease' -
Training AI programs, known in the industry as large language models (LLMs), involves scraping vast quantities of text or images from the internet.
This information is broken into trillions of tiny machine-readable chunks, known as tokens.
When asked a question, a program like ChatGPT selects and assembles tokens in a way that its training data tells it is the most likely sequence to fit with the query.
But even the best AI tools generate falsehoods and nonsense, and critics have long expressed concern about what would happen if a model was fed on its own outputs.
In late July, a paper in the journal Nature titled "AI models collapse when trained on recursively generated data" proved a lightning rod for discussion.
The authors described how models quickly discarded rarer elements in their original dataset and, as Nature reported, outputs degenerated into "gibberish".
A week later, researchers from Rice and Stanford universities published a paper titled "Self-consuming generative models go MAD" that reached a similar conclusion.
They tested image-generating AI programs and showed that outputs become more generic and strafed with undesirable elements as they added AI-generated data to the underlying model.
They labelled model collapse "Model Autophagy Disorder" (MAD) and compared it to mad cow disease, a fatal illness caused by feeding the remnants of dead cows to other cows.
- 'Doomsday scenario' -
These researchers worry that AI-generated text, images and video are clearing the web of usable human-made data.
"One doomsday scenario is that if left uncontrolled for many generations, MAD could poison the data quality and diversity of the entire internet," one of the Rice University authors, Richard Baraniuk, said in a statement.
However, industry figures are unfazed.
Anthropic and Hugging Face, two leaders in the field who pride themselves on taking an ethical approach to the technology, both told AFP they used AI-generated data to fine-tune or filter their datasets.
Anton Lozhkov, machine learning engineer at Hugging Face, said the Nature paper gave an interesting theoretical perspective but its disaster scenario was not realistic.
"Training on multiple rounds of synthetic data is simply not done in reality," he said.
However, he said researchers were just as frustrated as everyone else with the state of the internet.
"A large part of the internet is trash," he said, adding that Hugging Face already made huge efforts to clean data -- sometimes jettisoning as much as 90 percent.
He hoped that web users would help clear up the internet by simply not engaging with generated content.
"I strongly believe that humans will see the effects and catch generated data way before models will," he said.
M.Anderson--CPN